当我们使用 @ConditionalOnMissingBean / @ConditionalOnBean注解去给某个 bean 注入赋予条件时,那在条件判断时我们需要确保条件判断过程所需的环境已准备好。
举个例子
下面的代码中有两个配置类,涉及两个 Bean 的注入
配置类 ConfigA 需要注入一个 A,注入 A 没有条件,直接注入
1
2
3
4
5
6
7
8
class ConfigA {
@Bean(name = "a")
public A a() {
return new A();
}
}
配置类 ConfigB 需要注入一个 B,注入 B 有条件,只有当容器中没有 A 时才符合注入条件并进行注入
1
2
3
4
5
6
7
8
9
class ConfigB {
@Bean
@ConditionalOnMissingBean(name = "a")
public B b() {
return new B();
}
}
这时候就会产生一个疑问?
注入 B 的时候,Spring 是如何知道容器中是否已经存在 A 了。。。
结论
如果 ConfigA 和 ConfigB 都是用 @Configuration 标注的普通配置类,那注入 B 的条件判断 @ConditionalOnMissingBean 结果是不确定的。
原理分析
Spring 配置类是有加载顺序的,Spring是根据加载顺序去判断容器中是否存在指定Bean
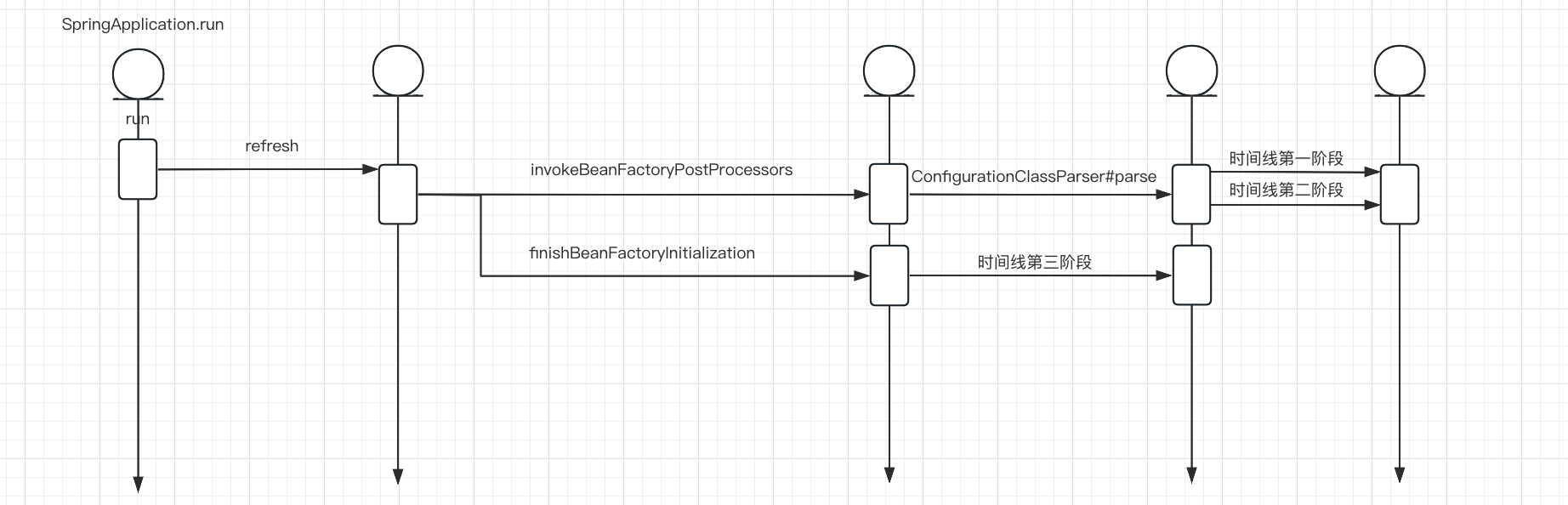
总的时间线
总的时间线共分为三部分
- 加载所有的@Component类,自然包括(@Service、@Controller、@Configuration…),并有序保存
- 按照上述保存的有序集合,遍历每一个@Component类中的每一个method,识别@Bean,注册 BeanDefinition
- 遍历所有的BeanDefinition,进行实例化
从上述时间线可以看到,解析 @ConditionalOnMissingBean 注解发生在时间线的第二部分。
在扫描到 @ConditionalOnMissingBean 注解时,会判断当前条件是否满足,满足则对当前 Bean 进行注册,而判断满足的条件就是根据注册保存的 BeanDefinition 集合去判断的。
因此,如果当前条件所依赖的 Bean 已经被扫描过了,并保存到了 BeanDefinition 集合中,那 Spring 就能正确的判断到 Bean 的存在。若当前条件所依赖的 Bean 还没有被扫描到,那 BeanDefinition 集合中就找不到,就会产生误判的情况,造成程序错误。
所以,@ConditionalOnMissingBean 要想正确被判断,我们就需要保证类的顺序性,保证当前依赖的 Bean 所在的类必须在本类之前被加载,而保证类的加载顺序,这就是第一部分做的事情。
时间线细粒度分析
1. 加载@Component类
上述分析中最重要的就是这部分,只要这部分的顺序性保证好了,那后续就不能出问题
这块代码的入口在 org.springframework.context.annotation.ConfigurationClassParser::parse
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public void parse(Set<BeanDefinitionHolder> configCandidates) {
for (BeanDefinitionHolder holder : configCandidates) {
BeanDefinition bd = holder.getBeanDefinition();
try {
if (bd instanceof AnnotatedBeanDefinition) {
parse(((AnnotatedBeanDefinition) bd).getMetadata(), holder.getBeanName());
}
else if (bd instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) bd).hasBeanClass()) {
parse(((AbstractBeanDefinition) bd).getBeanClass(), holder.getBeanName());
}
else {
parse(bd.getBeanClassName(), holder.getBeanName());
}
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to parse configuration class [" + bd.getBeanClassName() + "]", ex);
}
}
this.deferredImportSelectorHandler.process();
}
上述入口的逻辑可以看到,又分为了两部分,一部分是 parse,另一部分是 deferredImportSelectorHandler.process
步骤一:parse
下述代码就是 parse 做的事情,第一个进来的类是启动类。
有3个重要的全局变量
- configurationClasses,使用的是有序Map,这块保存的就是加载的@Component类,具有有序性,因此我们其实保证的就是这个集合中类的顺序,时间线第二部分就是有序遍历这个集合进行的。
- deferredImportSelectorHandler,和入口的第二部分有关。
- importStack,这是扫描的精髓,基于栈的形式递归当前入口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
private final Map<ConfigurationClass, ConfigurationClass> configurationClasses = new LinkedHashMap<>();
private final DeferredImportSelectorHandler deferredImportSelectorHandler = new DeferredImportSelectorHandler();
private final ImportStack importStack = new ImportStack();
protected final SourceClass doProcessConfigurationClass(
ConfigurationClass configClass, SourceClass sourceClass, Predicate<String> filter)
throws IOException {
if (configClass.getMetadata().isAnnotated(Component.class.getName())) {
// Recursively process any member (nested) classes first
processMemberClasses(configClass, sourceClass, filter);
}
// Process any @PropertySource annotations
for (AnnotationAttributes propertySource : AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), PropertySources.class,
org.springframework.context.annotation.PropertySource.class)) {
if (this.environment instanceof ConfigurableEnvironment) {
processPropertySource(propertySource);
}
else {
logger.info("Ignoring @PropertySource annotation on [" + sourceClass.getMetadata().getClassName() +
"]. Reason: Environment must implement ConfigurableEnvironment");
}
}
// Process any @ComponentScan annotations
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
if (!componentScans.isEmpty() &&
!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {
for (AnnotationAttributes componentScan : componentScans) {
// The config class is annotated with @ComponentScan -> perform the scan immediately
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// Check the set of scanned definitions for any further config classes and parse recursively if needed
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}
}
// Process any @Import annotations
processImports(configClass, sourceClass, getImports(sourceClass), filter, true);
// Process any @ImportResource annotations
AnnotationAttributes importResource =
AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class);
if (importResource != null) {
String[] resources = importResource.getStringArray("locations");
Class<? extends BeanDefinitionReader> readerClass = importResource.getClass("reader");
for (String resource : resources) {
String resolvedResource = this.environment.resolveRequiredPlaceholders(resource);
configClass.addImportedResource(resolvedResource, readerClass);
}
}
// Process individual @Bean methods
Set<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(sourceClass);
for (MethodMetadata methodMetadata : beanMethods) {
configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass));
}
// Process default methods on interfaces
processInterfaces(configClass, sourceClass);
// Process superclass, if any
if (sourceClass.getMetadata().hasSuperClass()) {
String superclass = sourceClass.getMetadata().getSuperClassName();
if (superclass != null && !superclass.startsWith("java") &&
!this.knownSuperclasses.containsKey(superclass)) {
this.knownSuperclasses.put(superclass, configClass);
// Superclass found, return its annotation metadata and recurse
return sourceClass.getSuperClass();
}
}
// No superclass -> processing is complete
return null;
}
上述逻辑比较多,简单概括做的事情
- 扫描自身、父类是否用注解@Component标注,对扫描到的类递归执行当前操作
- 扫描@PropertySource,并加载到Environment
- 扫描@ComponentScan,并扫描涉及到相关路径的所有类,对扫描到的类递归执行当前操作
- 扫描@Import,对扫描到的类递归执行当前操作
- 扫描@ImportResource,并加载到Environment
上述操作的每一步都会将扫描到的组件类添加到全局变量 configurationClasses 中。
由于当前操作基于递归实现,因此上述操作的有序性是得不到保证的。
这块核心的是步骤四,扫描@Import,下述代码是扫描@Import的逻辑
在看下述代码时可以先了解一下@Import的功能
@Import注解可以导入三种类
普通类
实现ImportSelector接口的类
这个接口的主要作用是批量导入,实现接口 selectImports,可以看到返回值是一个数组,这里需要返回多个类的全限定类名,实现批量导入
实现ImportBeanDefinitionRegistrar接口的类
这个接口的主要作用是提供 BeanDefinition 注册 Bean 的逻辑
了解了关于 @Import 的功能,就可以看下述代码了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
private void processImports(ConfigurationClass configClass, SourceClass currentSourceClass,
Collection<SourceClass> importCandidates, Predicate<String> exclusionFilter,
boolean checkForCircularImports) {
if (importCandidates.isEmpty()) {
return;
}
if (checkForCircularImports && isChainedImportOnStack(configClass)) {
this.problemReporter.error(new CircularImportProblem(configClass, this.importStack));
}
else {
this.importStack.push(configClass);
try {
for (SourceClass candidate : importCandidates) {
if (candidate.isAssignable(ImportSelector.class)) {
// Candidate class is an ImportSelector -> delegate to it to determine imports
Class<?> candidateClass = candidate.loadClass();
ImportSelector selector = ParserStrategyUtils.instantiateClass(candidateClass, ImportSelector.class,
this.environment, this.resourceLoader, this.registry);
Predicate<String> selectorFilter = selector.getExclusionFilter();
if (selectorFilter != null) {
exclusionFilter = exclusionFilter.or(selectorFilter);
}
if (selector instanceof DeferredImportSelector) {
this.deferredImportSelectorHandler.handle(configClass, (DeferredImportSelector) selector);
}
else {
String[] importClassNames = selector.selectImports(currentSourceClass.getMetadata());
Collection<SourceClass> importSourceClasses = asSourceClasses(importClassNames, exclusionFilter);
processImports(configClass, currentSourceClass, importSourceClasses, exclusionFilter, false);
}
}
else if (candidate.isAssignable(ImportBeanDefinitionRegistrar.class)) {
// Candidate class is an ImportBeanDefinitionRegistrar ->
// delegate to it to register additional bean definitions
Class<?> candidateClass = candidate.loadClass();
ImportBeanDefinitionRegistrar registrar =
ParserStrategyUtils.instantiateClass(candidateClass, ImportBeanDefinitionRegistrar.class,
this.environment, this.resourceLoader, this.registry);
configClass.addImportBeanDefinitionRegistrar(registrar, currentSourceClass.getMetadata());
}
else {
// Candidate class not an ImportSelector or ImportBeanDefinitionRegistrar ->
// process it as an @Configuration class
this.importStack.registerImport(
currentSourceClass.getMetadata(), candidate.getMetadata().getClassName());
processConfigurationClass(candidate.asConfigClass(configClass), exclusionFilter);
}
}
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to process import candidates for configuration class [" +
configClass.getMetadata().getClassName() + "]", ex);
}
finally {
this.importStack.pop();
}
}
}
上述代码逻辑简单整理:
-
判断要导入的类是否实现ImportSelector接口
-
判断是否实现DeferredImportSelector接口
这里就比较核心了,如果实现了DeferredImportSelector接口,则将当前的Selector注册到全局变量deferredImportSelectorHandler中。先不进行扫描
-
若不实现DeferredImportSelector接口,执行方法selectImports,将方法返回的数组中所有类都进行扫描
-
-
判断要导入的类是否实现ImportBeanDefinitionRegistrar接口
-
上述2个接口都没有实现,那就是导入的普通类,递归执行前面的扫描流程
步骤二:deferredImportSelectorHandler
通过步骤一可以得出,这里面保存的都是实现DeferredImportSelector接口的导入类。
这块的逻辑也是对deferredImportSelectorHandler中保存的类进行扫描处理。
那站在顺序性的角度考虑,这块逻辑中扫描的类的顺序肯定比步骤一的要晚。
可以得出结论,要想调整扫描顺序,让别的类在本类之前加载,那就可以让别的类在步骤一中加载,本类在步骤二中加载。
要想在步骤一中加载,需要用@Component修饰类
要想在步骤二中加载,需要一个实现DeferredImportSelector接口的导入类,将本类的全限定类名进行返回。
这时候自动装配类的作用就凸显出来了
Spring 若要开启自动装配,需要使用注解@EnableAutoConfiguration去修饰。
而注解@EnableAutoConfiguration又导入了一个AutoConfigurationImportSelector类,并且AutoConfigurationImportSelector类实现于DeferredImportSelector接口。
1
2
3
@Import(AutoConfigurationImportSelector.class)
public @interface EnableAutoConfiguration {
}
1
2
3
4
5
6
7
8
9
10
11
12
public class AutoConfigurationImportSelector implements DeferredImportSelector{
@Override
public String[] selectImports(AnnotationMetadata annotationMetadata) {
if (!isEnabled(annotationMetadata)) {
return NO_IMPORTS;
}
AutoConfigurationEntry autoConfigurationEntry = getAutoConfigurationEntry(annotationMetadata);
return StringUtils.toStringArray(autoConfigurationEntry.getConfigurations());
}
}
所有可以得出,自动装配类是在第二步骤中进行扫描的,自动装配类的加载顺序低于普通配置类
那要保证顺序,就可以让条件依赖的Bean使用普通配置类,本类使用自动装配类。
如果条件依赖的Bean也是自动装配类,那就可使用自动装配类的特性,进行自动装配类之前的顺序调整,比如(@AutoConfigureBefore、@AutoConfigureAfter、@AutoConfigureOrder)。
2. 扫描@Component类中每个method
这块逻辑的入口是 org.springframework.context.annotation.ConfigurationClassBeanDefinitionReader::loadBeanDefinitions
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
class ConfigurationClassBeanDefinitionReader {
/**
* 入参就是时间线第一部分加载的组件类
*/
public void loadBeanDefinitions(Set<ConfigurationClass> configurationModel) {
TrackedConditionEvaluator trackedConditionEvaluator = new TrackedConditionEvaluator();
for (ConfigurationClass configClass : configurationModel) {
loadBeanDefinitionsForConfigurationClass(configClass, trackedConditionEvaluator);
}
}
private void loadBeanDefinitionsForConfigurationClass(
ConfigurationClass configClass, TrackedConditionEvaluator trackedConditionEvaluator) {
if (trackedConditionEvaluator.shouldSkip(configClass)) {
String beanName = configClass.getBeanName();
if (StringUtils.hasLength(beanName) && this.registry.containsBeanDefinition(beanName)) {
this.registry.removeBeanDefinition(beanName);
}
this.importRegistry.removeImportingClass(configClass.getMetadata().getClassName());
return;
}
if (configClass.isImported()) {
registerBeanDefinitionForImportedConfigurationClass(configClass);
}
for (BeanMethod beanMethod : configClass.getBeanMethods()) {
loadBeanDefinitionsForBeanMethod(beanMethod);
}
loadBeanDefinitionsFromImportedResources(configClass.getImportedResources());
loadBeanDefinitionsFromRegistrars(configClass.getImportBeanDefinitionRegistrars());
}
}
这块的逻辑主要有以下部分:
- 判断当前类是否需要跳过,依赖于类上的条件,比如我们经常在类上添加条件@ConditionalOnClass、@ConditionalOnProperty……
- 是否是导入类,将导入类本身注册为BeanDefinition
- 遍历每一个method,扫描判断每一个method所修饰的注解,比如@Bean、@Autowire、@Scope、@ConditionalOnMissingBean…..并将当前Bean注册为BeanDefinition。
注册到BeanDefinition时保存的位置是BeanDefinitionRegistry的默认实现 DefaultListableBeanFactory中的全局变量beanDefinitionMap中,@Conditional条件判断就是判断这里面有没有目标Bean,若加载的比较晚,那肯定找不到,这也是场景中导致问题的根本原因。
1
2
3
4
5
6
7
public class DefaultListableBeanFactory extends BeanDefinitionRegistry {
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256);
private volatile List<String> beanDefinitionNames = new ArrayList<>(256);
}
3. 实例化Bean
这块逻辑的位置在 org.springframework.beans.factory.support.DefaultListableBeanFactory::preInstantiateSingletons
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
public class DefaultListableBeanFactory extends BeanDefinitionRegistry {
private volatile List<String> beanDefinitionNames = new ArrayList<>(256);
@Override
public void preInstantiateSingletons() throws BeansException {
if (logger.isTraceEnabled()) {
logger.trace("Pre-instantiating singletons in " + this);
}
// Iterate over a copy to allow for init methods which in turn register new bean definitions.
// While this may not be part of the regular factory bootstrap, it does otherwise work fine.
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
// Trigger initialization of all non-lazy singleton beans...
for (String beanName : beanNames) {
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
if (isFactoryBean(beanName)) {
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
if (bean instanceof FactoryBean) {
FactoryBean<?> factory = (FactoryBean<?>) bean;
boolean isEagerInit;
if (System.getSecurityManager() != null && factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged(
(PrivilegedAction<Boolean>) ((SmartFactoryBean<?>) factory)::isEagerInit,
getAccessControlContext());
}
else {
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean<?>) factory).isEagerInit());
}
if (isEagerInit) {
getBean(beanName);
}
}
}
else {
getBean(beanName);
}
}
}
// Trigger post-initialization callback for all applicable beans...
for (String beanName : beanNames) {
Object singletonInstance = getSingleton(beanName);
if (singletonInstance instanceof SmartInitializingSingleton) {
StartupStep smartInitialize = this.getApplicationStartup().start("spring.beans.smart-initialize")
.tag("beanName", beanName);
SmartInitializingSingleton smartSingleton = (SmartInitializingSingleton) singletonInstance;
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
smartSingleton.afterSingletonsInstantiated();
return null;
}, getAccessControlContext());
}
else {
smartSingleton.afterSingletonsInstantiated();
}
smartInitialize.end();
}
}
}
}
这块主要做的事情是:
-
遍历每一个 beanDefinition,判断是否抽象、单例、懒加载,并对符合条件的 beanDefinition 进行实例化,完成 Bean 的注入。
每个符合条件 beanDefinition 都会被调用一次 getBean 接口,找不到就会根据 beanDefinition 创建 Bean
-
为所有合适的 Bean 触发初始化后回调
总结
- @ConditionalOnMissingBean 判断的时候,是按照注册BeanDefinition的顺序进行判断的,BeanDefinition的顺序是由类的加载顺序保证的。这个流程中所有Bean都还没有实例化。
- 对于使用注解@ConditionalOnMissingBean、@ConditionalOnBean去对某个Bean的注入增加条件时,需要保证依赖的Bean是优先于当前类进行加载的。
- 如何控制加载顺序?
- 自动装配类的加载顺序是晚于普通配置类的
- 自动装配类之前的加载顺序可以使用@AutoConfigureBefore、@AutoConfigureAfter、@AutoConfigureOrder进行保证。
常用注解的加载时机
-
@Component
普通组件类,步骤一 parse 中加载
-
@Configuration
功能和@Component一致,叫@Configuration只是为了起个别名,标志特定分类的组件,和@Controller、@Service一致
-
@Import(xxx.class)
-
若导入的类没有实现 DeferredImportSelector 接口
普通组件类,功能和@Component一致,唯一的区别就是导入的类可以不用加@Component去标注。
-
若导入的类实现了 DeferredImportSelector 接口
延迟加载,步骤二deferredImportSelectorHandler的时候加载,加载晚于普通组件类
自动装配类就属于这种方式,但Spring给自动装配类增加了排序的特性,自动装配类之间可以排序。
-
-
@Enablexxx
常见于通过@Enable开头的注解,用于某个功能的开启。
这种实现本质上就是通过一个见名知意的注解去包装多个注解的功能,和把里面包装的注解写出来没区别,具体还是要看里面包装的注解做了什么事情
1 2 3
@Import(AutoConfigurationImportSelector.class) public @interface EnableAutoConfiguration { }
-
@AutoConfiguration
无任何实质性的作用,只是把@Configuration、@AutoConfigureBefore、@AutoConfigureAfter这三个注解包装成一个注解,标识这是一个自动装配类,方便自动装配类之间的排序。
但和上述@Enablexxx有个区别,Spring认这个注解,Spring在步骤一parse中对@ComponentScan的扫描阶段,发现此类如果用@AutoConfiguration标注,就会认为你是一个自动装配类,不进行扫描,跳过当前类
-
@AutoConfigureBefore、@AutoConfigureAfter、@AutoConfigureOrder
只生效于自动装配类,用于自动装配类之间的排序
自动装配类的配置
自动装配类有两种配置方式
-
resources/spring.factories
key为EnableAutoConfiguration的全限定类名
value为自动装配类的全限定类名
1 2
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ com.example.c.config.CConfig
-
resources/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports
里面一行一行的填自动装配类的全限定类名
1
com.example.c.config.CConfig
源码解析位置
1 2 3 4 5 6 7 8 9 10 11 12 13
public class AutoConfigurationImportSelector implements DeferredImportSelector{ protected List<String> getCandidateConfigurations(AnnotationMetadata metadata, AnnotationAttributes attributes) { List<String> configurations = new ArrayList<>( SpringFactoriesLoader.loadFactoryNames(getSpringFactoriesLoaderFactoryClass(), getBeanClassLoader())); ImportCandidates.load(AutoConfiguration.class, getBeanClassLoader()).forEach(configurations::add); Assert.notEmpty(configurations, "No auto configuration classes found in META-INF/spring.factories nor in META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports. If you " + "are using a custom packaging, make sure that file is correct."); return configurations; } }
常见问题
-
有一个类,既用@Configuration标注,又配置成了自动装配类,那他的解析时机发生在哪?
Spring在步骤一parse中对@ComponentScan的扫描阶段,会经过一系列的过滤器,其中一个是自动配置类的过滤器
这个过滤器的判断条件是,如果当前类用@Configuration标注,并且修饰的注解有@AutoConfiguration,或者配置成了自动装配类,那就跳过当前类的扫描
因此,这种场景下,此类扫描的时机应是走自动装配类扫描的逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
public class AutoConfigurationExcludeFilter implements TypeFilter, BeanClassLoaderAware { @Override public boolean match(MetadataReader metadataReader, MetadataReaderFactory metadataReaderFactory) throws IOException { return isConfiguration(metadataReader) && isAutoConfiguration(metadataReader); } private boolean isConfiguration(MetadataReader metadataReader) { return metadataReader.getAnnotationMetadata().isAnnotated(Configuration.class.getName()); } private boolean isAutoConfiguration(MetadataReader metadataReader) { boolean annotatedWithAutoConfiguration = metadataReader.getAnnotationMetadata() .isAnnotated(AutoConfiguration.class.getName()); return annotatedWithAutoConfiguration || getAutoConfigurations().contains(metadataReader.getClassMetadata().getClassName()); } protected List<String> getAutoConfigurations() { if (this.autoConfigurations == null) { List<String> autoConfigurations = new ArrayList<>( SpringFactoriesLoader.loadFactoryNames(EnableAutoConfiguration.class, this.beanClassLoader)); ImportCandidates.load(AutoConfiguration.class, this.beanClassLoader).forEach(autoConfigurations::add); this.autoConfigurations = autoConfigurations; } return this.autoConfigurations; } }
-
如果一个类用@AutoConfiguration注解修饰,但没有通过file文件的方式配置为自动装配类,那此类是什么时机被扫描的
和上述逻辑一致,检测到使用@AutoConfiguration修饰,则在步骤一parse中会跳过当前类的扫描。
但在步骤二中,又在自动装配类中没有找到当前类,则当前类不会被扫描。